Can Using Quotes in Articles Hurt Your Blog Post Rankings?
Published by Kenny Novak • Content Marketing • Posted August 22, 2019 ContentPowered.com
ContentPowered.com

Duplicate content has long been a boogeyman for marketers, ever since the apocalypse that was the Panda updates in 2011. For nearly a decade now, people have lived in fear of duplicate content and its ability to destroy the search ranking of a site.
There are a lot of misconceptions about what is and isn’t duplicate content, and how bad the penalties can be. All people remember from eight years ago is the outcry when thousands upon thousands of websites cried out and were suddenly silenced. Unlike the people of a doomed planet, though, these websites weren’t worth the space they took up on the internet. Good riddance to them.
What Duplicate Content Actually Means
So what is and what isn’t duplicate content? Here’s a quick test.
- Site A has a guide you really like. You want to reference it on Site B, so you copy three paragraphs and paste them as a quote in your article, surrounded by your own content.
- Site A has a guide you really like. You approach them and ask if you can syndicate it on your domain, and they agree. You publish the entire guide as-is, with a canonical link pointing to their domain.
- Site A has a guide you really like. You copy the guide and post it on your Site B, without a canonical link.
- You have just created Site A. A marketing firm you contracted to promote it copies your homepage and distributes it as a press release, making its content appear on sites B through Z.
Which of these is duplicate content? Depending on your definition of duplicate content, all of them can be, but what we’re talking about is Google’s definition.
In scenario 1, yes, you’re directly copying and pasting some of the content of another site onto your site. However, it’s just a small amount of content. Google doesn’t care. This scenario is perfectly fine.

Why doesn’t Google care? Well, they know for one thing that it’s perfectly fine to quote and cite passages from another source. I’ve done it before when quoting Facebook or Google help center articles, for example. I link to the original source, I quote the relevant passage, and I’m good to go.
This is true stretching all the way back into the antiquated world of books and academic papers. You cannot produce new research or new study without referencing what exists elsewhere. Thus, quoting and citations have to be fine.
There’s also the case where what you’re quoting is not a reference article or paper or blog, but the data itself. You can’t exactly edit the data to be unique, that disrupts the data and can misrepresent it. Obviously, Google doesn’t want to encourage misrepresentation.
Plus, well, there are only so many possible combinations of words in the English language. The internet is basically the million monkeys with a million typewriters scenario, writ large. Two people can write the same sentence when they’re discussing the same topic, and it’s not theft or plagiarism or copied content, it’s simply two great minds thinking alike.

Of course, the chances of two entire 2,000-word blog posts being identical and independently created is slim to none, but that’s not what we’re talking about here.
In scenario 2, what we’re talking about isn’t copied content, but syndicated content. Syndication is when multiple sites publish the same content, all of them referencing back to the original version. This is explicitly what the rel=”canonical” link attribute and meta entry is for.
Syndication can be a good way to get traffic to your site. You’re publishing great content, which can show up in Google, and which your users may value, even though you didn’t produce it.
There are two keys that form the difference between copied content and syndicated content. These are the canonicalization and permission.

Canonicalization simply requires you to add the rel=”canonical” link to your page’s meta data, pointing at the URL of the original version of the content. This tells Google of the official source of the content, when it’s not you.
Permission, meanwhile, simply means making sure the original source of the content gives you permission to use it in this way. If you don’t have permission to use it, the original content creator can file a DMCA notice to have your version taken down, and can pursue legal action if you do not comply with the takedown notice.
In scenario 3, meanwhile, the process is more akin to theft. You like the content, you take it and publish it, and you hope no one notices. Well, Google will notice, you can guarantee that much. You could block Google’s bots – though you probably won’t get them all, since they have spies they don’t announce – but then your copied content isn’t going to rank and isn’t going to be found, so it does you no good to steal it.
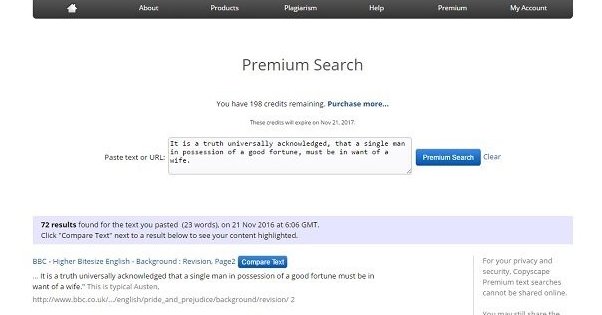
Even then, if you do this for one blog post on a site with 100 other blog posts you created on your own, Google probably isn’t going to care. What Google cares about, typically, is value across the whole site. The reason thousands of sites were killed off in the Panda updates of 2011 was because those sites had no original content of their own. They didn’t provide unique value, they simply stole content and attempted to monetize it.
Now, that’s not to say that your theft wouldn’t be noticed. Anyone who finds the copied content can report it to the original copyright holder, who can then pursue legal action starting with asking you to remove it and ending with a lawsuit. You’re not in the right just because Google doesn’t automatically penalize you.
In scenario 4, we have copied content in the opposite direction. I stole this scenario from Neil Patel’s article on the topic, 3 Myths About Duplicate Content. The exact scenario happened and it blacklisted the original site, even though the original site was the source of the content that was spread around. It was a misunderstanding, and it was eventually fixed, but the point remains: the site had no value outside of the content that was published in 100 other places, and thus the site had no value in the search rankings.
What Google Cares About
At the end of the day, Google only cares about one thing: value to the user. They don’t care where that value comes from or how you put it together. That’s why a lot of things that might seem like they’re going against the rules are perfectly fine.
For example: a post on Yahoo News is identical to a post on Time Magazine’s website, both of which have rel=”canonical” links pointing to themselves. Google sees two identical pieces of content, both claiming to be the original, but neither is penalized. Why not?
Two reasons. First, both of them credit the original source, and the original author. They aren’t trying to represent the content as their own, they’re saying “this is a post from the AP”. It’s syndicated content, and Google knows it.
Second, Google knows that different people like to read different news sites for their information. Syndicating one piece of legitimate news from one source across different affiliated news organizations means more people are exposed to the value of the news. Sure, it dilutes the value of the piece, but each different news site has different selections of content and different ways of adding value.
Duplicate content will penalize a site when that site has no original value of its own. If you run a blog, but all you do is steal blog posts from 100 different sources, you’re not providing your own value. Each of those sources has their own value, but the only potential unique value you could provide is having it all in one place. Chances are, that’s not good enough. And if it is, well, that’s what blog aggregators do.
Google often ranks sites based on dozens of different factors, and when they have the same content posted on them, Google will omit them. In the case of the news article I listed above, it shows up on a dozen different sites on Google, but you can bet it’s actually syndicated on hundreds more. It does no one any good to see hundreds of copies of the same post in their search results, so after a few of the top options, Google starts looking for other possible value sources.
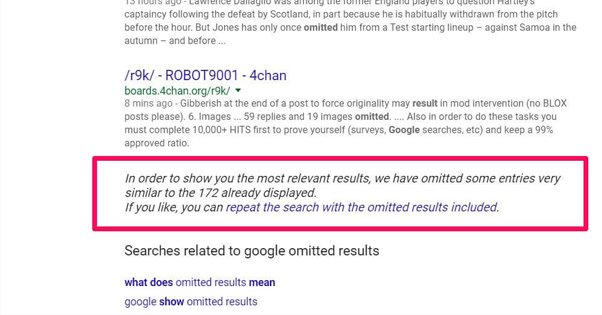
Sites that steal content are almost universally ranked lower than the original sources of those sites. Often, they’re ranked so much lower that they never appear in the first five pages of Google, long after their position holds any value. In the rare instance where a site has stolen content and ranks higher than the original source, the original source can report the scraper and have it dealt with.
How to Quote Content in an SEO Friendly Way
Quotes in general are not going to hurt your SEO. However, if you want to be doubly and triply sure that you’re not going to penalize yourself by quoting someone else, here are some steps you can take.
First, take as little of the source content as possible. Instead of “quoting” an entire blog post, quote a few relevant paragraphs. Better yet, instead of quoting a few paragraphs, quote one paragraph and write your own write-up of the context that makes it make sense. Copy as little of the original content as possible to get your point across.

Second, add your own original content to the post surrounding the quoted content. The more of your own original value you have on the page, the better off you are. Even if you’re writing something like “50 SEO Experts Opinions on Onions” with quotes you sourced from posts all of those marketers posted on their own blogs, you can add value. Copy their quote, but then write a description of where the quote is from, the context of the quote, and what you think it means as a key takeaway.
Third, use the proper format for quotes. WordPress, in the Gutenberg Block Editor, has a specific Blockquote Block you can use for a quoted passage. If you’re not using WordPress, or if you’re using an older version, you can use block quote tags in your code directly. When you flag the content as a quote, Google knows it’s a quote, and knows not to penalize you for it. I mean, they don’t need the HTML to tell them that, but it doesn’t hurt. It also flags the quote as a quote to your readers.
Fourth, make sure to cite the original source. Attribution is the main difference between reference and theft. You can do this in a number of ways. You can say “from X:” and put the quote. You can put the quote and then add “—from X”. You can even just use a footnote at the bottom of your page, though such citations are less effective than in-text citations.
Fifth, just don’t worry so much about it.
- “Remember, Google has 2,000 math PhDs on staff. They build self-driving cars and computerized glasses. They are really, really good. Do you think they’ll ding a domain because they found a page of unoriginal text?” – Anthony Crestodina, via neilpatel.com
The fact is, if you’re embarking on a campaign of content theft as a way to fill out a blog, you’re going to be penalized with invisibility. If you’re quoting a few passages as a way to add value to your own content, you’re perfectly fine. Duplicate content isn’t nearly the boogeyman it seems to be.

Kenny is a blogger and networking professional. He uses blogging and content marketing as a launchpad for small businesses looking to grow their online presence.