




At its core, a Knowledge Graph is a structured system that organizes facts, entities, and the relationships between them in a way that machines can actually understand. Rather than simply matching keywords on a page to keywords in a search query, a Knowledge Graph lets a search engine or AI system understand context - that a person is a founder of a company, that a company is headquartered in a city, that a city is in a country, and so on - it's less about strings of text and more about meaning, connections, and the real world.
Google introduced its own Knowledge Graph back in 2012, and since then, the concept has become foundational to how modern search works - and increasingly, how AI-powered tools interpret and present information. For website owners and managers trying to get traction with AI Optimization (AIO) and Answer Engine Optimization (AEO), the Knowledge Graph isn't a background technicality - it's one of the most important systems determining whether your brand, business, or content gets understood, trusted, and surfaced.
This glossary entry will explain what a Knowledge Graph is, where the concept came from, how it operates within search and AI ecosystems, and what it means for your site's ability to show up in an increasingly answer-driven web.
Quick Answer
A Knowledge Graph is a structured representation of real-world entities and the relationships between them, stored as interconnected nodes and edges. It organizes information semantically, allowing machines to understand context and meaning. Knowledge graphs power features like Google's search results, virtual assistants, and recommendation systems. They combine data from multiple sources into a unified, queryable network, enabling reasoning, inference, and discovery of hidden connections. Key components include entities (people, places, concepts), attributes, and relationships that define how entities connect.
What a Knowledge Graph Actually Is
A knowledge graph is a structured network of entities and the connections between them. An entity can be a person, a place, a brand, a product, or an abstract concept - basically anything that can be named and described.
What makes a knowledge graph different from a standard list or flat database is the relationships. Kind of like the way your brain doesn't store memories as separate files - it connects them, so thinking about one thing pulls up related things.
For example, a knowledge graph might know that an author wrote a book, that the book belongs to a genre, that the genre is popular in a country, and that the author lives in that country, and each of those facts is connected to the others in a way that a simple spreadsheet can't capture.
That distinction matters quite a bit for search engines, AI systems, and any tool that needs to know context instead of just match words.

This is also where knowledge graphs part ways with keyword lists. A keyword list tells a machine what words appear on a page. A knowledge graph tells a machine what those words mean and how the things they describe are connected to each other - it's a fundamentally different kind of information.
Your website, your brand, and the topics you cover may already be represented - or not represented - as entities within these systems. How accurately you're described in a knowledge graph can have an effect on how your content gets interpreted and surfaced. This connects closely to how your blog's E-A-T score is evaluated by search engines.
The mechanics become quite a bit easier to follow once the core concept clicks.
How Google's Knowledge Graph Changed Search
Google launched its Knowledge Graph in May 2012. But the groundwork had been laid years earlier. Two projects - DBpedia and Freebase - started in 2007 and worked to turn scattered web data into structured, connected information. Google acquired Freebase in 2010 and used it as a foundation to build something far bigger.
At launch, the Knowledge Graph held 570 million entities and 18 billion facts. That alone was a big deal. But the growth that followed made those numbers look modest.
By mid-2016, Google had expanded the Knowledge Graph to 70 billion facts. Then by May 2020, it had grown to 500 billion facts spread across 5 billion entities. To put that in perspective, that's roughly 100 facts for every person on Earth.
The scale matters because it reflects a change in what Google is actually doing when it processes a search. Before the Knowledge Graph, search engines worked by matching the words in your query to words on a page. Type "jaguar," and the engine would find pages that contained the word "jaguar." It had no way to know if you meant the animal, the car brand, or a sports team.
The Knowledge Graph changed that. Instead of matching strings of text, Google started to know things - real-world entities, places, businesses, and concepts - and could connect "jaguar" to its related meanings and use context to work out what a person was looking for.

Google described this at the time as moving from "strings to things." That phrase captures the change well. Search stopped being a word-matching exercise and became something quite a bit closer to intent.
This also changed what appears on a search results page. Knowledge Panels - those information boxes that appear to the right of search results - pull directly from the Knowledge Graph. When you search for a known person or business and see a structured summary with facts, images, and related links, that's the Knowledge Graph at work. This is also closely tied to zero-click search, where users get answers directly on the results page without visiting any site.
The ripple effect on how Google ranks and interprets content has been significant. A page that talks about a topic is now evaluated in the context of what Google already knows about that topic. The words on the page are one factor. But Google also evaluates whether it can connect your content to the entities and relationships it has already mapped out. Understanding this is part of why earning Google Sitelinks on your blog has become a meaningful signal of authority and structure.
Where Your Website Fits Into the Knowledge Graph
Websites, businesses, authors and local businesses can all become recognized entities inside a knowledge graph. Once it connects enough dots, your brand can become an entity with its own place in the graph.
Consider a local bakery trying to get seen online. If the business name, address and phone number are listed the same way on Google Business Profile, Yelp and the bakery's own website, Google starts to build a confident picture of that business as a real, honest entity. That consistency does quiet work, and it matters.
The same idea applies to personal brands. An author with a Wikipedia page, a steady bio across publishing platforms and links from respected websites is much easier for Google to find and trust than one with scattered or conflicting information online.
Structured data markup is one of the most direct ways to help this process along. Adding schema markup to your website - things like Organization, Person, or LocalBusiness schema - gives Google a signal about who you are and what you do. It's basically an introduction in a language Google understands well.
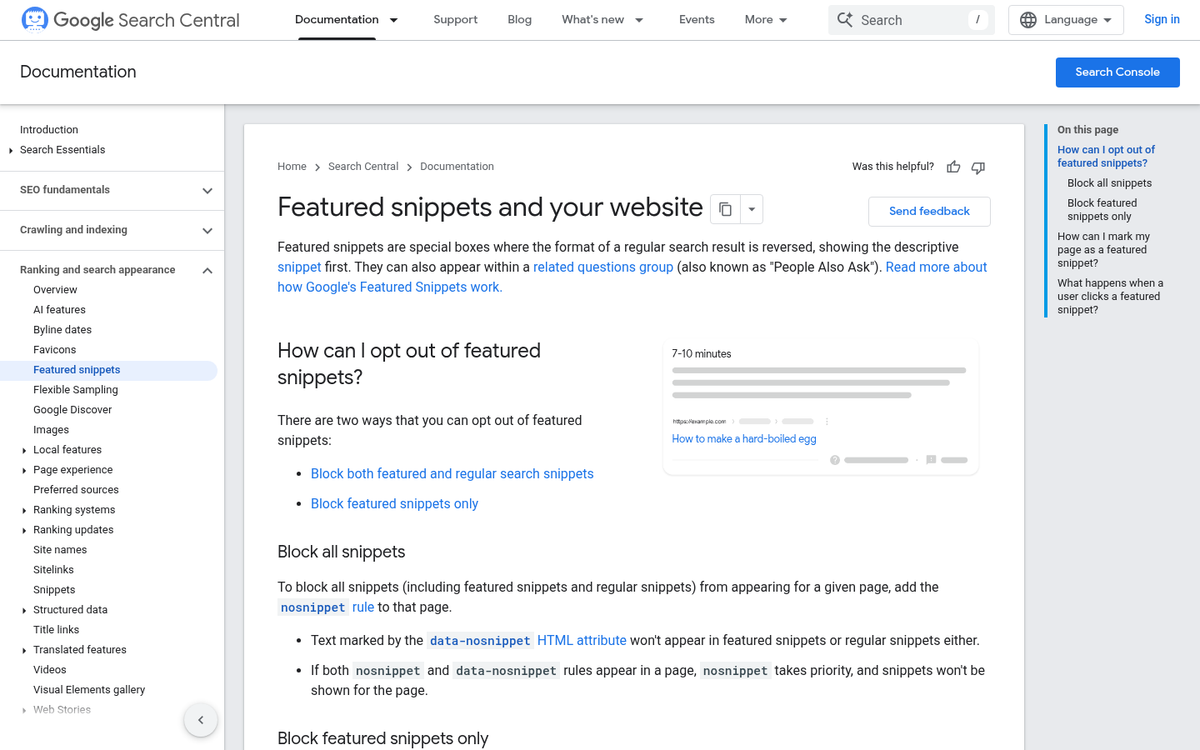
Why Inconsistent Information Causes Problems
When your business name appears differently across the web, it creates uncertainty during what's called entity resolution - the process Google uses to match pieces of information to a single entity. A listing that says "Joe's Bakery LLC" on one site and "Joes Bakery" on another might read as two separate things to an algorithm.
This is not a minor technical detail. Inconsistent information can stop Google from confidently associating your website with your entity, which limits how prominently you appear in knowledge panels, local packs and AI-generated answers. Getting this right is more foundational than most people know.
Authoritative backlinks also play a role here. Links from trusted, well-established websites signal to Google that other recognized entities are vouching for yours. A mention on a local news site or an industry directory carries more weight than a link from an unrelated blog.
A presence on Wikidata or Wikipedia can add further credibility. These sources are reference points that Google and other AI systems draw from to verify and expand their understanding of an entity. You don't need a full Wikipedia article - even a Wikidata entry with accurate, sourced information can help establish your entity in the graph.
Knowledge Graphs and Their Role in AI-Generated Answers
AI Overviews, featured snippets and answer engines don't scan web pages and pull out random text. They lean heavily on structured, entity-rich data. That data traces back to Knowledge Graph relationships.
When Google's systems need to answer a question directly, they look for facts they can trust. That trust comes from how well an entity is established, how reliably sources point to it, and how it connects to related entities. A business or person that's well-represented in the Knowledge Graph is a safer bet for an AI system to cite.
Back in 2014, Google scientists described a system called Knowledge Vault that went further than the original Knowledge Graph by automatically collecting facts from across the web and scoring each one by confidence level. The higher the confidence score, the more likely a fact was treated as reliable. That logic hasn't gone away - it's very much part of how modern AI systems choose what to surface and what to skip.
Why entity signals matter for AI-generated replies: ranking in search results is no longer the only goal. A site seen as a well-connected, credible entity with consistent information across the web stands a better chance of being pulled into an AI answer.
An AI Overview tries to give a user the best direct answer without sending them anywhere. To do that, it has to trust its sources. A site with vague authorship, inconsistent name or address facts, or no entity presence is easy to pass over in favor of one that's established. Inconsistent signals can also raise red flags with Google in ways that affect how trustworthy your content appears.

Featured snippets work in a similar way. Google lifts a passage because it matches the query and because the source has enough authority to back it up. Entity recognition factors into that authority assessment. The right SEO tools can help surface content that's more likely to be chosen for these placements.
Answer engines like Perplexity and SearchGPT also pull from structured data and established sources. They're not doing keyword matching alone - they're making judgment calls about which sources are credible enough to cite. A site that's treated as a known entity in the wider web of structured data has an advantage here.
The connection between Knowledge Graphs and AI-generated answers is direct and growing. As AI tools take on more of the answer-delivery role in search, the entities that are well-documented and well-connected will get more of that visibility.
Structured Data Markup and Entity Signals You Can Control
One of the most direct things you can do is add Schema.org markup to your website - this tells search engines what your content is about, not through guessing, but through structured, machine-readable code. It's one of the clearest ways to help knowledge graphs connect your entity to the right information.
Different schema types serve different purposes. An Organization schema identifies your business, its name, logo, and contact details. A Person schema works for authors or public figures. LocalBusiness is the right fit for physical locations. Article schema helps search engines understand editorial content and connect it to the right author or publisher entity - and if you're writing blog posts, using proper heading tags alongside that markup reinforces your content structure.
| Schema Type | What It Describes | When to Use It |
|---|---|---|
| Organization | Business identity, logo, contact info | Any business or brand website |
| Person | Individual's name, role, affiliations | Author pages, personal websites |
| LocalBusiness | Physical location, hours, address | Brick-and-mortar businesses |
| Article | Editorial content and authorship | Blog posts, news articles |
The sameAs property is worth mentioning - it lets you link your schema markup to authoritative external profiles, places like Wikidata, LinkedIn, or your Wikipedia page if one exists. This helps search engines confirm that the entity on your site is the same one referenced elsewhere on the web.
Consistency matters quite a bit here. Your business name, address, phone number, and description should match across every platform - your website, Google Business Profile, social accounts, and any data directories. Inconsistent information creates doubt for automated systems that are trying to build a reliable picture of your entity.
The scale of this matters too. Gartner predicted that graph technologies would power 80% of data and analytics innovations by 2025, up from just 10% in 2021. That growth means entity-based systems are becoming the foundation of how information gets processed and surfaced.
Schema markup is something you can do directly, without waiting for third-party recognition - it's a helpful, low-barrier way to send stronger entity signals to the systems that shape how your brand gets understood and represented. Tools like the AEO Content Grader can also help you evaluate how well your content is optimized for these kinds of entity-based signals.
Making Your Site Legible to the Machines That Matter
If you are ready to start building your Knowledge Graph presence, here are the moves that matter most:
- Claim and complete your Google Business Profile with accurate, consistent information
- Implement structured data markup using Schema.org to define your entities clearly
- Create a strong About page that explicitly describes your organization, its people, and its purpose
- Standardize your NAP data (name, address, phone number) across every directory and platform
- Build authoritative backlinks and mentions from trusted sources in your industry
- Link your web presence to established entities like Wikipedia, Wikidata, and industry databases where applicable
- Publish consistent, expert-driven content that reinforces your topical authority over time
None of this happens overnight. But the compounding effect is real. Every structured signal you add, every authoritative mention you earn, and every piece of content you publish that shows genuine expertise can bring your entity more into focus for search engines and AI systems - the work of making your website a trusted, recognized source in a web that's increasingly mediated by algorithms trying to determine who actually knows what they are talking about.
FAQs
What is a Knowledge Graph?
A Knowledge Graph is a structured system that organizes entities, facts, and relationships in a way machines can understand. Unlike keyword matching, it captures meaning and context - connecting people, places, brands, and concepts to each other.
When did Google launch its Knowledge Graph?
Google launched its Knowledge Graph in May 2012, starting with 570 million entities and 18 billion facts. It has since grown to over 500 billion facts across 5 billion entities.
How does a Knowledge Graph affect AI-generated answers?
AI tools like Google's AI Overviews rely on structured, entity-rich data from Knowledge Graphs to determine trustworthy sources. Brands well-represented in the Knowledge Graph are more likely to be cited in AI-generated answers.
How can I get my website into a Knowledge Graph?
Add Schema.org markup to your site, standardize your business name and contact details across all platforms, earn authoritative backlinks, and link your profiles to trusted sources like Wikidata or Wikipedia.
Why does inconsistent business information cause problems?
Inconsistent details confuse the entity resolution process, making it harder for Google to confidently connect your website to a single entity. This can reduce your visibility in Knowledge Panels, local search, and AI-generated answers.