Key Takeaways
- Automated traffic hit 51% of all web traffic in 2024, with bad bots alone accounting for 37% of internet traffic.
- AI crawlers are growing rapidly, with GPTBot requests up 147% and Meta-ExternalAgent up 843% in one year.
- Over 13% of AI bot requests ignored robots.txt in Q2 2025, making server-level blocking increasingly necessary.
- Blocking search engine crawlers like Googlebot removes your site from search results, so selective blocking is essential.
- Effective bot defense layers include robots.txt, server firewalls, behavioral CAPTCHAs, WAFs, and regular traffic audits.
Understanding Web Bots in 2026: The Good, the Bad, and the Ugly
A large portion of the traffic that arrives on your site is going to come from non-human sources - and in 2026, that's more true than ever. According to the Imperva 2025 Bad Bot Report, automated traffic accounted for 51% of all web traffic in 2024, surpassing human-generated activity for the first time in a decade. Bad bots alone - involved in scraping, credential stuffing, and fraud - account for 37% of all internet traffic.
You can still filter and analyze bot traffic inside Google Analytics, but no tool is 100% accurate. There are always bots trying to get around bot filtering methods, and the tactics they use are getting more sophisticated by the year.
Good Bots
A bunch of the bots that visit your site are perfectly benign, even beneficial. The most obvious example: the way Google discovers new content online, and the way they tell when a piece of content has changed, is by deploying a massive swarm of software constantly crawling the web. This swarm follows links, jumps from site to site, and indexes new and updated content.
Google's crawlers are complex, with a deep set of rules that govern their behavior. The NoFollow attribute on a link makes that link effectively invisible to Googlebot. They won't follow it, and consequently won't record what's on the other side. They'll also respect the NoIndex directive if you want specific pages - or your entire site - kept out of the index.
Every major search engine runs its own crawlers. Bing (and Bing-powered search experiences) operates a fleet with similar behavior. Beyond traditional search engines, you now have an entirely new category of good bots worth knowing about: AI crawlers. Bots like OpenAI's GPTBot, Anthropic's ClaudeBot, Google's extended crawlers for AI products, and Meta's Meta-ExternalAgent are actively crawling the web to train large language models and power AI-generated answers. According to Cloudflare Radar, from July 2024 to July 2025, raw requests from GPTBot rose 147%, while requests from Meta-ExternalAgent rose a staggering 843%.
Whether you consider AI crawlers "good" bots is increasingly a matter of debate - more on that below.
Bad Bots

On the other end of the spectrum, you have the bad bots. Some crawlers fall into this category because they intentionally seek out and index content on your site that you don't want displayed publicly. They ignore robots.txt directives entirely, and they're not going away.
The problem with bots that index content that should remain hidden is that it opens the door for hackers who might use access to those files to compromise your system. They can identify specific versions of specific files indexed through these crawls and target your site if it's running outdated software.
There are also spam bots. These bots crawl your site for comment fields, contact forms, and any other open input. They fill out these fields with predefined messages - usually affiliate links, spam links, or outright scams. There's an ongoing arms race between spam bot developers and anti-spam tools like Akismet, which attempt to recognize bot behavior and content before it pollutes your site.
One increasingly serious category is scraper bots. These bots harvest your content - articles, product listings, pricing data - often feeding it directly into AI training pipelines or competitor tools without your knowledge or consent. This is a major and growing concern in 2026, with 79% of top news sites now blocking AI training bots via robots.txt, and 71% blocking AI retrieval bots, according to BuzzStream research.
Then there are the botnet bots. These are malware-infected computers slaved to a hacker's command, often rented out to other bad actors. Botnets remain the leading driver of DDoS attacks - whenever you hear about a major site being taken offline, a botnet is usually involved. Blocking these is difficult because the traffic originates from ordinary-looking IP addresses belonging to infected devices.
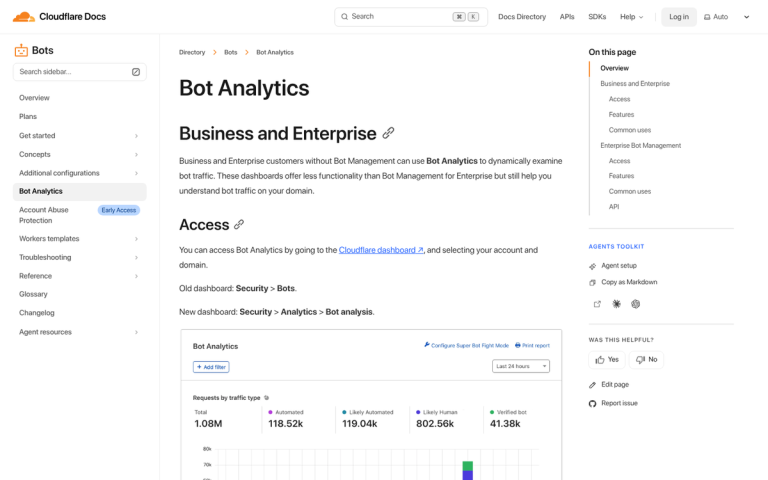
API-targeting bots are also a growing threat that many site owners overlook entirely. According to Imperva, in 2024, 44% of advanced bot attacks hit APIs directly, compared to just 10% targeting standard web applications. If you're running any kind of API - even a basic one for a mobile app or third-party integration - this is something you need to take seriously.
The Gray Area: AI Bots and robots.txt
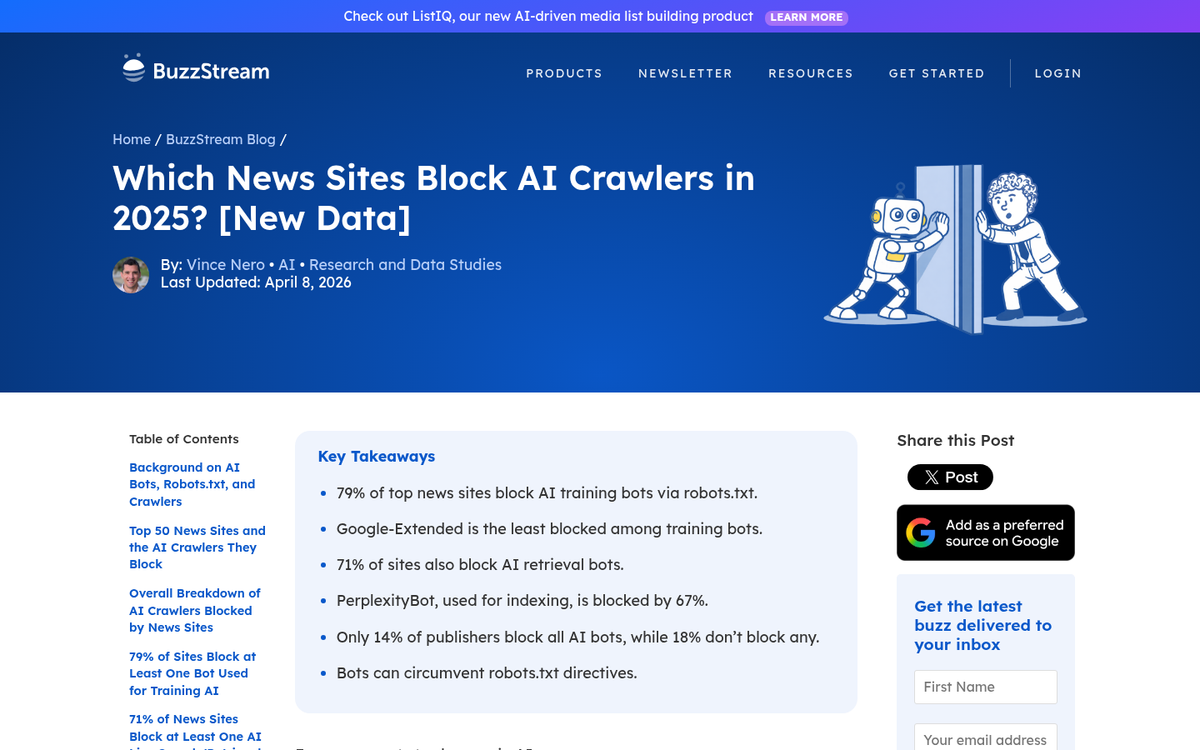
One of the biggest shifts since this post was first written is the rise of AI crawlers that don't play by the rules. According to TollBit's data, 13.26% of AI bot requests ignored robots.txt directives in Q2 2025, up sharply from just 3.3% in Q4 2024. PerplexityBot in particular has been flagged repeatedly for ignoring disallow rules, and is now blocked by 67% of sites that actively manage their bot access.
This puts website owners in a genuinely new position. robots.txt used to be a reasonably reliable signal. Today, if you're trying to keep AI crawlers off your content, you need to go further than a robots.txt entry alone.
Should You Block Bots?
The answer is still: it depends on the bot. Blocking Googlebot means your site disappears from search results - effectively deindexing yourself by choice. That's obviously not what you want.
But you definitely want to block spam bots, aggressive scrapers, and any crawler that's harvesting your content without adding value in return. You'll also want to think carefully about which AI crawlers you're comfortable allowing. Some, like Google's AI crawlers, may help surface your content in AI-powered search results. Others are purely extracting data for training purposes with no traffic benefit to you whatsoever.
DDoS protection is a separate challenge entirely and can't be handled with the same lightweight methods you'd use to block a scraper.
Fighting Bad Bots
There are several layers of defense worth implementing.
First, maintain an updated robots.txt file. It won't stop the worst offenders, but it remains the baseline standard. You can block all bots from your entire site, restrict specific directories, or target individual user agents by name. Many site owners are now adding explicit disallow rules for GPTBot, Meta-ExternalAgent, PerplexityBot, and other AI crawlers. Keep in mind that robots.txt is advisory - bad bots can and do ignore it.
For more aggressive blocking, you'll want to work at the server level - either through your hosting control panel, .htaccess rules, or ideally through a dedicated firewall. Adding known bad bot IP ranges and user agent strings to a deny list can significantly reduce junk traffic, though it requires ongoing maintenance as bad actors rotate IPs.
For spam bots on forms, modern CAPTCHA solutions like Google's reCAPTCHA v3 (which works invisibly in the background based on behavioral signals) and hCaptcha are your best options as of 2026. Traditional image-based CAPTCHAs have largely been defeated by AI-powered solvers, so invisible behavioral analysis is now more effective than asking users to click on traffic lights. Best practices for registration forms can also help you reduce bot submissions.
Consider a WAF (Web Application Firewall) if you're not already using one. Services like Cloudflare (even on the free tier), Sucuri, or similar tools do a lot of the heavy lifting automatically - identifying and blocking bad bot traffic based on continuously updated threat intelligence. Given that nearly half of advanced bot attacks now target APIs, a WAF is no longer just for enterprise sites.
Finally, make a habit of auditing your bot traffic regularly. Tools like Cloudflare Analytics, Google Search Console, and your server logs can all reveal patterns worth investigating. If you're seeing unusual spikes, it's also worth learning how to stop fake traffic in Google Analytics. Staying on top of what's crawling your site - and why - is one of the more underrated aspects of running a healthy website in 2026.