The problem cuts right to something deeply uncomfortable about how AI tools work. These systems were trained on massive amounts of data pulled from across the web, and that data had a cutoff point. Whatever was true about your business when that information was grabbed is what the AI learned - and it does not automatically know that things have changed since then. You could have updated your website, your Google Business Profile, and every directory listing on the internet, and an AI tool might still be reciting outdated facts like they are gospel.
So the obvious question becomes: can you actually do anything about it? The answer is more complicated than a simple yes or no, and rather than spend time chasing an answer that might not be out there - or miss one that does exist - this post breaks down how outdated business information ends up in AI replies, what options are realistically available to you, and what you can do to cut back on the damage while working toward a longer-term fix.
Key Takeaways
- AI models learn from data with a fixed cutoff, so they can confidently repeat outdated business information even after you've updated everything.
- You cannot directly remove information from a trained AI model; incorrect facts are embedded in billions of parameters, not stored as editable database entries.
- Businesses can push back by submitting correction requests to AI platforms and maintaining accurate, well-structured web presences that retrieval-based AI tools can reference.
- AI platforms using real-time web retrieval offer businesses a more direct path to surfacing correct information than static training-based models do.
- Growing regulatory pressure, including the EU AI Act's strict 2025 compliance rules, is pushing AI developers toward stronger data correction mechanisms.
Why AI Keeps Showing Wrong Business Information
AI models learn from giant amounts of text data grabbed up to a point in time. After that cutoff, the model stops learning - it doesn't browse the web in real time or update itself when your business changes its address or drops a product line. Whatever was true when the data was grabbed is what the model remembers.
This is why AI can confidently tell you your old phone number or describe a service you stopped running two years ago. The model isn't malfunctioning - it's doing what it was built for - it's just working from a snapshot of the internet that no longer matches reality.
The difference between what AI knows and what's actually true can grow fast for businesses that change locations, rebrand, or restructure their services. A franchise that opens new locations, a clinic that changes ownership, a SaaS company that retires a product - these businesses are vulnerable to AI repeating outdated facts with confidence.

And this isn't a small or isolated problem. A study by Neil Patel tested 600 prompts across six AI models and found that ChatGPT answered accurately only 59.7% of the time - a significant accuracy gap for something increasingly treated as a reliable research tool.
The root cause is structural. AI models are trained once - or updated periodically - and the information gets baked in at a deep level - it's not stored like a database entry you can go in and edit. The model has absorbed patterns and associations from the data, so incorrect business facts become embedded alongside everything else it learned.
Some AI tools do pull from live web sources to supplement their answers. But even those tools can surface outdated information if the underlying web content hasn't been updated or if the model leans on cached knowledge instead of a fresh search result. Understanding the difference between good traffic and bad traffic becomes especially relevant when AI is sending visitors based on stale information about your business.
This context matters for anyone trying to address the problem. The reason fixing AI misinformation about your business is tough has everything to do with how the information got there - which is what the next section gets into. If you're also struggling to understand where visitors are actually coming from, it helps to know why traffic sources sometimes show as unknown in your analytics.
The Hard Truth About Removing Data from a Trained AI Model
Here's the uncomfortable part. Once an AI model has been trained on a dataset, that information gets encoded into the model's parameters - billions of numerical weights that shape how it responds. There is no database row to delete, no file to pull, no switch to flip.
This matters quite a bit for business owners who assume a quick correction request will do the job. The wrong address or the closed branch isn't sitting somewhere as a helpful entry waiting to be updated - it's mixed together into the model in a way that can't be undone without retraining the whole thing, an enormously expensive and time-consuming process that AI businesses don't do on demand for individual businesses.
The challenge is known in the field as "machine unlearning" - the idea of teaching a model to forget information without having to start from scratch.

Work in this space is ongoing but not yet standard. Fraunhofer ISST and Fujitsu Research have looked into federated unlearning, which attempts to remove the influence of data from a trained model in a more targeted way - it's a promising direction. But it's still an emerging area of study and not something that's available to a business owner who just wants their old phone number to stop appearing in AI replies.
The difference between what scientists are looking at and what actually works in a deployed AI product is wide. Most large language models in public use aren't retrained frequently, and even when they are, there's no guarantee that corrected information in newer training data will overwrite older patterns the model already learned.
For a business owner hoping to go directly to the source and scrub the record, that path doesn't really exist in any helpful sense. What does exist are some indirect strategies that can slowly push better information into the spaces where AI tends to look - and that's where how retrieval models decide what to cite becomes worth understanding before the next section picks up.
What Businesses Can Actually Do Today to Push Back
You have more options - even if none of them are instant fixes. The key is to work on multiple fronts at once instead of waiting for one answer to do the heavy lifting.
The first lever is to go directly to the source. Some AI platforms let you submit correction requests through developer portals or feedback forms - slow and not guaranteed to change anything. But it puts the issue on record and can eventually change how a model is updated or fine-tuned - it's worth doing even if the response timeline is vague.
The second lever is to strengthen your authoritative web presence. AI retrieval tools - the kind that pull live data to supplement their replies - tend to prioritize well-structured, credible sources. Keeping your Google Business Profile accurate is one of the most helpful steps you can take. Your official website should also be kept up to date with the latest information, and adding schema markup (structured data that helps search engines and AI tools read your content correctly) gives these systems a cleaner signal to work with.
The table below shows how some of the main AI platforms manage corrections and data freshness - it's honest about the gaps.
| AI Platform | Accepts Corrections | Uses Real-Time Data | Relies on Training Data Only |
|---|---|---|---|
| ChatGPT (GPT-4, no browsing) | Feedback form available | No | Yes |
| ChatGPT (with Browse) | Feedback form available | Yes, when enabled | No |
| Google Gemini | Feedback form available | Yes | No |
| Microsoft Copilot | Limited feedback options | Yes, via Bing | No |
| Meta AI | Feedback form available | Limited | Largely yes |
| Claude (Anthropic) | Feedback form available | No (as of 2024) | Yes |
Platforms that blend real-time retrieval with AI replies are your strongest ally here. If an AI tool is pulling live web data, a well-maintained business website has a direct path to changing what gets surfaced.
For static training-based models, the feedback path is the only door available to you and it moves slowly. Consistency with your web presence is the more reliable long-term play - tools that help you track website growth can make it easier to see what's working over time.
The Legal Pressure on AI Companies to Get This Right
The helpful steps businesses can take are one thing. But there's a much bigger force pushing this issue forward: regulation. Governments are not waiting for AI to sort itself out.
Europe's data privacy laws have been in effect since 2018, and they created the first friction around data removal from AI systems. Those laws gave businesses the right to request corrections or deletions of inaccurate data. But applying that to AI training data turned out to be legitimately tough. AI systems don't store information the way a database does, so "deleting" something from a model is not as easy as removing a row from a spreadsheet.
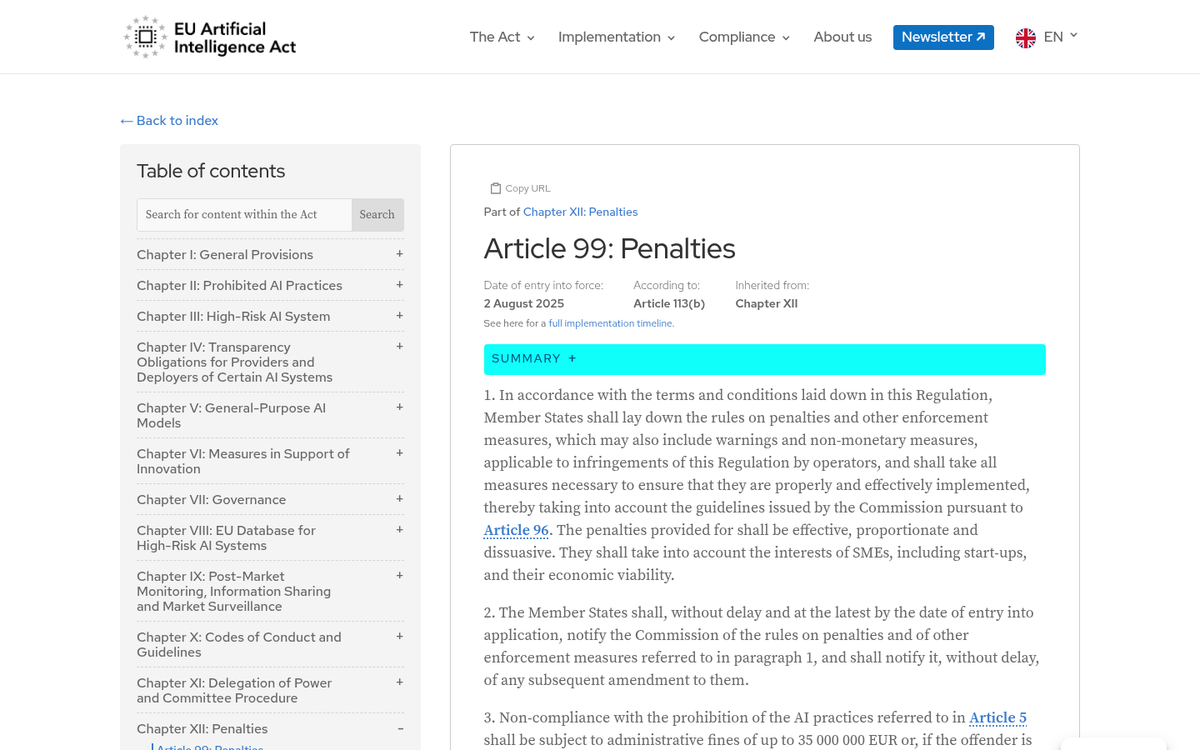
The EU AI Act raises the stakes further. From August 2025, it imposes strict compliance laws on AI systems used in business contexts, with fines reaching as high as €35 million for the most serious violations. That is not a warning shot - it's a structural change in how AI accountability works across the industry. AI developers will have much stronger legal incentives to build better data correction mechanisms into their products.
This lines up with what business leaders are already saying. A 2025 IBM Institute for Business Value report found that 43% of COOs named data quality as their top priority. These are not abstract problems - they represent financial damage traced directly to inaccurate or outdated information flowing through business operations.

If regulators across economies and large enterprises are treating data accuracy as a financial and legal priority, that has implications for any small or mid-sized business dealing with wrong information in an AI tool.
The pressure on AI developers to improve is real and growing. Businesses of any size have more standing than they might think to push back on inaccurate AI outputs, because the regulatory environment is building a framework that supports them in doing that. The landscape is not settled yet. But it's moving in a direction that treats bad data as a liability instead of an inconvenience.
Your Business Information Isn't Set in Stone - But You Have to Stay in the Fight
The most helpful thing you can do is control what you can control: keeping your authoritative sources accurate, consistent, and frequently updated. Your Google Business Profile, official website, and directories are the inputs that shape how AI systems represent your business over time. The cleaner and steadier those signals are, the faster outdated information loses its foothold. It's also worth periodically querying AI tools about your own business - treat it like a reputation audit and flag errors through whatever feedback or correction channels those platforms give you.
The wider community is also changing in your favor. Regulatory pressure around AI accuracy is growing, and AI developers are investing in faster, more reliable ways to update what their models know. The businesses that come out ahead will be the ones that stay well-educated about these changes instead of waiting to respond to them. One foundational step is making sure you can check the social signals of your website regularly, so you have a clear picture of how your brand presence reads across the web.