




Structured data lives in knowledge graphs - and one of the most influential sources feeding those graphs is Wikidata. With over 120 million entities and more than 1.65 billion statements, Wikidata functions as a universal registry for things that are out there in the world: places, organizations, products and concepts. Every entry in that registry is anchored by an identifier called a QID. Think of it as a permanent, machine-readable address - one that tells AI systems not just that your brand exists, but what it is, how it relates to other entities and why it should be included in a generated response.
For businesses operating without a Wikidata QID, the exposure danger is real. An AI model pulling from structured knowledge sources to answer "What companies make X?" or "Who are the leaders in Y industry?" won't guess your brand into existence. If you don't have a verified, well-connected entity record, you might basically be invisible to the systems shaping how millions of people now discover businesses and make decisions.
I'll break down how QIDs work, why they've become a critical component of AI-era brand strategy and what you can do to set up and strengthen your brand's presence across the knowledge graph ecosystem - starting with Wikidata.
Key Takeaways
- Wikidata QIDs serve as permanent, machine-readable identifiers that anchor brand entities across AI knowledge graphs and search systems.
- Brands without a QID risk invisibility in AI-generated responses, since systems can't reliably link names to verified facts without one.
- Key properties like instance of (P31), official website (P856), and inception date (P571) make brand entities legible and classifiable to machines.
- Linking your QID to external authority files like VIAF, ISNI, and GLEIF strengthens AI trust signals through corroborating, independent sources.
- Brands must audit their Wikidata items regularly, updating properties after mergers, rebrands, or leadership changes to maintain accurate graph relationships.
What a Wikidata QID Actually Is and Why AI Systems Care
A QID is an identifier that Wikidata assigns to every entity in its database. Your brand could be Q4567890. A city, a person, a scientific concept - each one gets its own Q number, and that number never changes or gets reused - it's the permanent address for that entity inside the knowledge graph.
Wikidata launched in 2012 and was funded by the Allen Institute for AI, Google, and the Gordon and Betty Moore Foundation, with an initial grant of €1.3 million - it was built to be machine-readable from day one, which is a big part of why AI systems gravitate toward it.

A lot of people confuse Wikipedia and Wikidata, so it's worth taking a second to separate them. A Wikipedia article is written prose meant for humans to read. A Wikidata item is a set of structured statements that machines can parse, like "brand X is an instance of a software company, headquartered in city Y, founded in year Z." Those two things can point to each other. But they are fundamentally different formats serving different purposes.
AI language models are trained on large datasets that pull from structured sources like Wikidata alongside unstructured text. A QID gives your brand a fixed anchor point in that relational structure.
Without a QID, your brand has no stable identity inside the knowledge graph. AI systems can still see your name in text. But they can't reliably link that name to a steady set of facts. The QID is what makes disambiguation possible - it separates your company from any other entity that shares a similar name or operates in a related space. If AI keeps getting your details wrong, a missing QID may be part of why ChatGPT gets your company info wrong.
How Knowledge Graphs Use Your QID to Understand Your Brand
Knowledge graphs don't store information the way a database does. They store it as a web of connected statements, and every statement follows the same basic pattern: a subject, a predicate, and an object. "Brand X was founded by Person Y" is one statement. "Brand X operates in Industry Z" is another. Wikidata holds around 1.65 billion of these statements, all linked together into something AI systems reason through.
Your QID is the anchor point for every statement that relates to your brand - it captures who founded the company, what category it belongs to, which products it makes, and how those things connect to other verified entities in the graph.
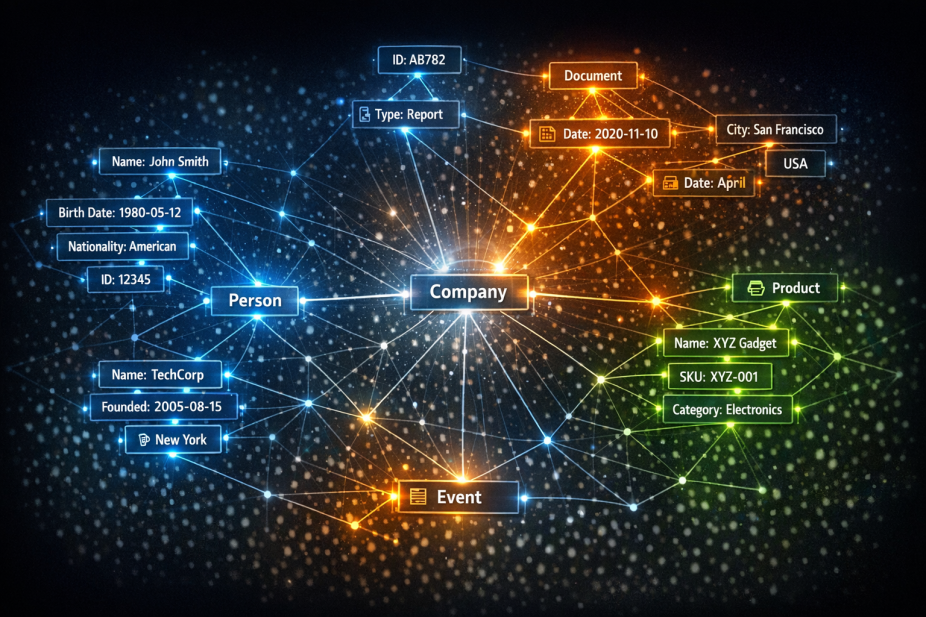
This is where entity disambiguation matters. Many brand names are shared with other things. A company called "Meridian" could be confused with a geographic term, a person's name, or a dozen other registered businesses. A QID removes that uncertainty because it refers to one entity and nothing else.
Consider what your brand's relationships look like when represented as a graph. Your founder connects to an education history, a location, and other businesses. Your products connect to categories, competitors, and use cases. Your headquarters connects to a city, a country, and regional market context, and each of those connections is a statement that helps AI systems place your brand accurately within a bigger web of meaning.
The more accurate those connections are in Wikidata, the more confidently an AI can find and describe your brand across different contexts. A sparse or missing entity leaves gaps that AI systems fill in on their own - sometimes incorrectly. A well-connected QID gives AI something concrete to work with, and that matters quite a bit when your brand appears in generated content, search features, or assistant replies.
The Core Properties That Make a Brand Entity Machine-Readable
Think of Wikidata properties as the structured data fields that tell AI systems what your brand is and how to categorize it, and each property has a PID - a unique identifier - and the values you assign to those properties are what make your entity legible to machines.
The most basic property is instance of (P31) - this tells knowledge graphs what type of entity you are. For a brand, you'd usually assign a value like "business (Q4830453)" or a more specific type if one fits. If you don't have this, your item floats without context.
Next up is official website (P856) - this anchors your Wikidata entity to your real-world web presence and gives AI systems a direct link to your authoritative source. It also helps connect your entity to other data sources that reference the same URL.
The inception date (P571) tells systems when your brand came into existence. A precise date is far more helpful than a vague year, so use the most specific date you can verify. Blank fields and approximate values cut back on how confidently a knowledge graph can interpret your entity.

| Property | PID | What It Signals | Example Value |
|---|---|---|---|
| Instance of | P31 | Entity type/classification | business (Q4830453) |
| Official website | P856 | Authoritative web presence | https://yourbrand.com |
| Inception date | P571 | When the entity was created | 2010-03-15 |
| External identifier | varies | Cross-system authority linkage | ISNI, GND, VIAF |
Beyond the basics, properties like industry (P452), headquarters location (P159), and founder (P112) add actual depth to your entity. These are what allow AI systems to place your brand accurately within a wider network of related entities and concepts, contributing directly to your overall entity authority.
Vague values do damage here. If a field can't be populated with something accurate and verifiable, it's better to leave it out than to fill it with a guess. External identifiers like ISNI, GND, and VIAF are especially valuable because they link your entity across multiple established authority systems.
Linking Your QID to Authority Files and External Identifiers
Once your core properties are in place, the next layer to add is external identifiers. Wikidata can link your brand entity to hundreds of authority files - databases that libraries, governments and academic institutions use to catalog real-world entities. Names like VIAF, GND, ISNI, the Library of Congress Name Authority File and WorldCat Identities might sound obscure. But AI systems treat them as trust signals.
Kind of like citations in an academic paper. The more credible, independent sources that point to the same entity, the more confidently an AI system treats that entity as well-established. A brand QID with no external identifiers is a single data point. A QID linked to five or six authority files is a web of corroboration.
Not every authority file will apply to every brand. A publishing house might prioritize VIAF and the Library of Congress. A product-focused company might find GLEIF (for legal entity identifiers) or OpenCorporates more helpful - it's worth spending time to research which databases are most relevant to your industry and adding those identifiers.
The most damaging mistakes here are easy to make. A mismatched name - even a small variation like "Inc." versus "Incorporated" - can signal inconsistency to automated systems that cross-reference these sources. An outdated identifier that no longer resolves to an active record is arguably worse than having no identifier at all, because it introduces a broken link into what should be a coherent entity profile. Removing outdated business information from AI is a separate challenge worth addressing alongside your Wikidata cleanup.
| Authority File | Best For |
|---|---|
| VIAF | Publishers, media companies, authors |
| ISNI | Creative organizations and individuals |
| GND | Brands with German-speaking market presence |
| GLEIF / LEI | Financial and corporate entities |
| OpenCorporates | Registered businesses across most jurisdictions |
Before you add any identifier to your Wikidata item, verify that it currently resolves and that the name on the external record matches your brand's legal or preferred name. Even small discrepancies can affect your overall brand authority score as AI systems evaluate the consistency of your entity data across sources.
Creating or Claiming Your Brand's Wikidata Item Without Getting It Deleted
Before you create a new Wikidata item for your brand, search closely to check if one already exists. A previous employee, a Wikipedia editor, or an automated bot may have already created an item for your organization. Duplicate items get flagged for merging and can create uncertainty for the knowledge graph systems that use clean, deduplicated data.
If no item exists, you are going to need to meet Wikidata's notability threshold. Your brand needs to be "notable" in the Wikidata sense - meaning it should have references from reliable, independent sources. Think news coverage, government registrations, industry databases, or an existing Wikipedia article. A brand that only appears on its own website is unlikely to pass review.
When you do create an item, write statements in a neutral, factual tone. The single biggest reason new items get deleted is that they read like marketing copy instead of structured data. Phrases that describe your brand as a leader or an innovator will raise red flags with Wikidata patrollers almost immediately.
Missing references are another fast path to deletion. Every claim you add should link to a verifiable source, and the Wikidata community takes this seriously. A statement with no reference is treated as unverifiable, which puts the whole item at risk.
Wikidata has an active volunteer patrol community that reviews new items and flags anything that looks promotional, unsourced, or structurally incomplete. To give your item the best chance of survival, include the core statements - the instance of, inception date, country, and official website - and add references from the start.
For organizations that need to work with Wikidata at scale, the Wikimedia Enterprise API is a legitimate path to explore - it was developed through collaboration with Wikimedia Deutschland and gives structured access to Wikidata content for commercial use cases - but it's not a way to edit or control your item. It does help you monitor and retrieve data reliably.
If your item does get merged or removed, that history is public and worth looking over to understand what went wrong.
Monitoring Your Entity's Health Across AI Knowledge Graphs
Once your Wikidata item is live and well-structured, the work does not stop. Your entity's accuracy depends on attention to it over time, and linked data systems will reflect your updates and your neglect.
The Wikidata Query Service, which launched on September 7, 2015, is one of the most helpful tools you have here - it lets you run SPARQL queries against the entire Wikidata database to check what statements are attached to your QID and how other entities reference yours. If that sounds technical, don't worry - there are pre-built query templates you can adapt without writing code from scratch.
Two other tools are worth learning about. Reasonator gives you a clean, readable view of any Wikidata item so you can scan for missing or outdated properties at a glance. Scholia is a better choice for tracking how your entity connects to related items, which matters when AI systems use those connections to build context around your brand.
The bigger strategic question is what happens when your brand changes. A merger, a rebrand, or a new product line can each break the relationships your entity has with other Wikidata items. If your company is acquired, the parent-subsidiary relationship needs to reflect that. If you rebrand, your item should carry a "formerly known as" statement instead of leaving the old name floating without context.
These graph relationships are what AI knowledge systems use to understand your brand's position in its industry.
Audit your Wikidata item at least twice a year. Check that your key statements still match your latest reality, that your external identifiers still resolve, and that no unsourced edits have introduced inaccurate claims. The Wikidata Query Service makes it easy to pull a full list of your item's properties in one view so you can scan everything faster.
Your QID is an asset. Treat it like one.
Your Brand Exists in the Graph - Now Make Sure AI Knows It
The path from understanding what a QID is to maintaining a well-linked Wikidata item is short. Search for your brand on Wikidata. If an item exists, review it for accuracy and completeness. If it does not, look at whether your brand meets the notability threshold and start building one. Every property you add - your industry, your founding date, your official website, your connections to people and places - is another signal that helps AI systems confidently surface and describe your brand in the answers they generate.
The semantic web is not a passing trend. As AI systems grow more refined, their reliance on structured, verifiable, interlinked data will only deepen. The businesses that invest in their knowledge graph presence now are building an asset that compounds over time - one that works quietly in the background, lending authority and visibility to every AI-generated brand mention, every knowledge panel, and every intelligent search result. That work begins with a single QID.


