Key Takeaways
- Content is automatically copyrighted upon creation under the Berne Convention; no formal notice is required, though one strengthens protection.
- Stolen content rarely hurts your Google rankings; established sites with strong E-E-A-T signals get priority over low-authority scrapers.
- AI-generated content adds new complexity: purely AI-generated work lacks copyright protection, and AI-spun copies of your content aren't considered original.
- When plagiarism occurs, escalate gradually: contact the site owner first, then their web host, then pursue DMCA takedowns as a last resort.
- Proactive defenses include adding copyright notices, embedding attribution links in RSS feeds, and indexing content quickly via Google Search Console.
As upstanding humans, we like to think the best of each other. We give each other the benefit of the doubt. We trust each other until that trust is betrayed. We're innocent until proven guilty. Unfortunately, it's a fact of life that betrayal and guilt do happen. In this particular instance, I'm talking about the problems that come up with online copyright, content ownership and plagiarism.
Plagiarism happens and it happens quite a bit. But most of the time it doesn't matter - maybe unintentional and dealt with, or maybe intentional but ineffectual.
Intentional and Unintentional Plagiarism
All online plagiarism can be categorized into unintentional or intentional plagiarism. Intentional plagiarism is pretty easy to identify. People know what they're doing and what they're doing is stealing your content with the intent of passing it off as their own - it's theft, it's illegal and you have legal recourse should you go after it.

Unintentional plagiarism comes from people who are too new or uneducated about Internet copyright to know what they're doing - it's tempting for a business to see a blog post they like and just take it. Sometimes they even attribute it to the source. But that's still illegal copying. The same thing happens all the time to images and art online and it's even worse on artists than it is on writers. If you want to share others' content the right way, learning how to create legal and ethical curated content is essential.
There's also the case where you as a blog owner could be responsible for unintentional plagiarism. What happens if you buy a post from a writer, just to find out months later that the piece was copied wholesale from somewhere else? And in 2026, there's a very new wrinkle: AI-generated content. Some site owners are unknowingly publishing AI output that closely mirrors existing published work and creates grey areas around originality that courts are still working through.
Myths and Truth: How Copyright Works

There's misinformation and mythology surrounding online copyrights and part of the problem is that new rulings continue to change what is and isn't a violation. Copyright law is a labyrinth and most of the biggest businesses try to get things settled out of court. AI has added a new layer of difficulty, with standard litigation in 2025 and 2026 between AI businesses and publishers over training data and generated content.
- Your work is automatically copyrighted just by existing on the Internet. Copyright is implied, due to the Berne Copyright Convention. You don't need to have a notice, though a notice does strengthen your protection by warning off people who don't know any better.
- Any time content is taken from someone and used without permission, it's a violation of copyright. The only exception is fair use. This means that it's still a violation if you don't charge for it, it's still a violation if the content was posted publicly, it's still a violation if the original owner doesn't aggressively pursue legal action, and so forth.
- Fair use remains a nuanced and often litigated concept. You can use short excerpts, like quotations, and those are generally considered fair use - though using quotes in articles can still affect your blog post rankings. You cannot reproduce an entire piece without explicit permission. Parody is protected, but derivative works that merely repackage your content are not.
- The primary legal recourse for a copyright violation remains the Digital Millennium Copyright Act (DMCA). DMCA takedown requests carry legal weight, and noncompliance can lead to further action. Google continues to process hundreds of millions of DMCA requests per year and acts on valid notices quickly.
- AI-generated content and copyright is a rapidly evolving area. The U.S. Copyright Office has clarified that purely AI-generated content without meaningful human authorship is not eligible for copyright protection, though human-authored content that incorporates AI assistance may still qualify. If someone is using an AI tool to spin or rewrite your content at scale, that does not make the resulting content original - in some cases, rewriting content the right way is the better approach rather than simply copying it.
Alleviating Google Ranking Concerns
If you're worried about your content being stolen and the copied content causing you to lose your Google ranking position, the danger remains low in most cases - but it's worth understanding the modern landscape.
Duplicate content problems from scraping are still handled well by Google in 2026. Google's systems are good at recognizing the original source and awarding ranking credit accordingly. If anything, the proliferation of AI-generated content at scale has made Google even more aggressive about recognizing and discounting thin, copied, or low-value content through its spam systems and helpful content guidelines, which were updated in 2024 and 2025.
The protection comes from a combination of things. The primary factor is indexation date. Even if a site stealing your content backdates its timestamp, Google's crawl history identifies which version appeared to be first and attributes original authorship to you.
Another factor is trust and authority. Most sites stealing content are thin, spammy and low-authority. Your site - if it's well-maintained, earns legitimate links and follows Google's guidelines - will be given the benefit of the doubt. With Google's increased emphasis on E-E-A-T (Experience, Expertise, Authoritativeness and Trustworthiness) since 2022, established sites have even more of an advantage over scrapers and content thieves.
The point is, 99% of the time, stealing your content won't hurt your search ranking - it may be annoying and brand-damaging, but those spam sites usually won't rank and very few will ever see them.
#1: Plagiarism of Blog Posts
Blog post scraping is easy to do, very hard to stop entirely and nothing to worry about in most cases. As mentioned, it won't hurt you in almost every scenario. In the rare case it does cause harm, you have legal, ethical and technical options to fix it - it's also worth mentioning that AI-powered scraping tools have made bulk content theft easier than ever, so the volume of scraped content online has increased - but Google's defenses against it have scaled accordingly.
#2: Plagiarism of Site Writing

Another source of written plagiarism comes from other forms of site writing. Someone could steal your product descriptions, just to give you an example. Or, you might have taken product descriptions straight from the manufacturer. Thin or duplicate product content can still hurt your rankings under Google's helpful content systems, so it's worth ensuring that all commercial copy on your site is original. If you're the original source and someone copies you, it's usually not going to hurt you.
#3: Plagiarism of Site Design
Now and then, someone will like your business model and copy you wholesale - sometimes even using AI tools to rapidly clone entire site structures, copy and design. I've seen full copies of sites posted with nothing but the name changed. Remedies are still available through DMCA and web host complaints and, in egregious cases, legal action.
#4: Plagiarism of Graphic Design and Visual Content
Stealing images remains extremely common and with AI image generation now widespread, there are new complications. People steal original images. But some are using AI tools to generate near-copies of original artwork or photography - an actively contested legal area. For easy image theft, the same DMCA and host complaint process applies. If you need a place to safely host your blog images for free, there are reliable options worth exploring. For AI-generated near-copies of your visual work, talk to a copyright attorney, as this is still being litigated.
Tools for Locating Stolen Content
Plagiarism happens all the time. Don't be surprised if you find your content posted on another site. Take rational action instead of knee-jerking into a bigger problem.
If you want to proactively monitor for stolen content, here are some tools you can use:
- Google Alerts. Set up alerts for unique phrases from each post you write. If you're using a distinctive headline or sentence, any new alert result is likely a sign of copied content. Always verify before taking action.
- Copyscape. Still one of the most widely used plagiarism detection tools. It finds partial matches and full copies of your content across the web, and is useful both for monitoring your own content and vetting writers before publishing.
- Originality.ai. A newer tool that has become popular among content teams for both plagiarism detection and AI content detection. Useful if you're concerned about AI-spun versions of your content appearing elsewhere.
- Ahrefs or Semrush backlink monitoring. If your content contains links back to your site, you'll see new referring domains appear in your backlink profile when that content is scraped and republished. This is a passive but effective way to detect theft.
- Google Search. You can periodically search for your exact titles or unique phrases in quotes to surface copied versions indexed by Google.
- TinEye and Google Reverse Image Search. Both are useful for tracking where your original images have been used without permission across the web.
Identifying the Thief
Once you've found your content posted without permission, you'll have to find who is responsible. The owner of the site is your target - the thief may be a hired writer who submitted stolen content and you won't be able to track that person down.
First, check if the site has public contact information. An accessible email address or social profile is the fastest and most direct path to resolution and its presence usually means you're dealing with an unintentional plagiarist instead of a deliberate bad actor.
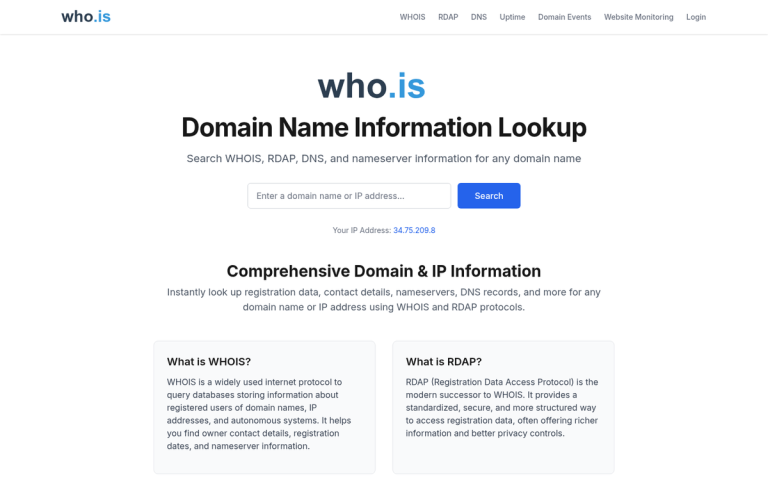
If there's no contact information, look up domain registration data. WHOIS lookup tools are still helpful, though privacy protection services have made this less reliable than it used to be. Many registrants now shield their personal information behind privacy proxies.
If WHOIS doesn't help, find their web host. Tools like HostingChecker or similar host lookup services can find the hosting provider from the domain name and provide a contact point to escalate to.
The High Road: Inform and Request
Contacting the site owner directly is your first and preferred strategy for resolving plagiarism problems and that's also the case with unintentional plagiarists. If you have direct contact information for the site owner, you can use it.
In your message, state that you found your content posted on their site without permission. Provide links to the infringing copy and your original and explain that copyright is implied by default - no notice is required for ownership to apply. Request that the content be removed promptly.

For images, you might prefer attribution over removal, depending on your preferences and how you license your work. For written content, removal is usually the cleaner outcome.
Before sending any takedown request, double-check that you actually hold the rights to the content in question. If you purchased content from a freelancer or a marketplace, review the terms of that agreement. Platforms have different licensing structures and sending a takedown letter when the other party has equal legal rights to use the content will undermine your position.
If the other party complies, you're done. If they push back, you can cite relevant copyright law or move on to the next strategy.
The Low Road: Undercut and Go to the Host
If the site owner doesn't respond, their contact information is false, or they refuse to cooperate, go directly to their web host. Hosting providers universally include copyright violation clauses in their terms of service - this protects them from liability under the DMCA and gives them every incentive to act quickly.

Contact the host's abuse or support team, identify the infringing site and provide links to the stolen content and your original. The vast majority of hosts will either contact the site owner and demand removal or take down the offending content themselves - this works quickly and reliably in most cases.
The Last Resort: Legal Action
If all else fails, legal action remains your final option. The first formal step is submitting a DMCA takedown request. Google's Search Console provides an easy process for submitting copyright removal requests and valid notices usually result in the infringing URLs being deindexed quickly. If content doesn't appear in search results, its harmful impact on your business drops to near zero.
In the rare case that a site stealing your content outranks you, has traffic, or is causing measurable commercial harm, you might consider pursuing a legal suit. It's expensive and time-consuming and copyright litigation has grown more complex with the addition of AI-related questions around originality and infringement. If you're thinking about this path, talk to a qualified copyright attorney - not a blog post.
Pre-emptive Protections
There are a few steps you can take to cut back on the effects of plagiarism before it can become a problem.
First, add a copyright notice to your site's footer - this deters unintentional plagiarists who mistakenly believe that unlabeled content is public domain. If you use WordPress, you may also want to review how footer links work in your theme while you're making changes there.
Second, consider embedding attribution links within your content itself. Some publishers include a discreet "originally published at [URL]" line in their RSS feeds, which means scrapers who pull content via RSS automatically republish that attribution - this turns scraping into a minor SEO benefit instead of a pure negative. You can learn more about the pros and cons of managing your RSS feed to make the most of this approach.
Third, publish and index your content faster. Using Google Search Console to request indexing of new posts immediately after publishing strengthens your timestamp claim as the original source. These tricks to improve indexing of your blog posts can help Google crawl your content quickly, making your priority date much clearer.
Fourth, build your brand and authority. The bigger and more trusted your site, the more Google's systems will default to treating you as the original source when duplicate content appears elsewhere. A strong E-E-A-T profile - demonstrated through authorship, steady publishing, earned social signals and a topical focus - is your best long-term defense against content theft mattering at all.
Fifth, stay away from disabling right-clicking or JavaScript tricks to block copying. These degrade the experience for legitimate users, are bypassed by anyone with basic technical knowledge and do nothing to deter determined scrapers using automated tools.